2. Dati della ricerca e materiali aperti
Di che cosa si tratta?
I dati della ricerca aperti sono dati accessibili, ri-utilizzabili, modificabili e ri-distribuibili liberamente per finalità accademiche, didattiche e non solo. Idealmente, i dati aperti possono essere ri-utilizzati o ri-distribuiti senza restrizioni, qualora la licenza lo permetta. In casi eccezionali, ad esempio per proteggere l’identità delle persone fisiche, sono stabilite delle restrizioni speciali o limitazioni all’accesso ai dati. La condivisione aperta dei dati ne aumenta l’esposizione contribuendo in questo modo a creare i presupposti per la verifica e la riproducibilità della ricerca nonché all’avvio di nuovi percorsi per una più ampia collaborazione. Al massimo, i dati aperti possono essere soggetti all'obbligo di attribuzione e condivisione (cfr. Open Data Handbook).
Fondamenti
I dati della ricerca sono spesso il risultato più prezioso di molti progetti di ricerca, possono infatti essere utilizzati come fonti primarie a sostegno della ricerca scientifica e consentono di estrapolare risultati sia teorici sia applicativi. Al fine di rendere replicabili, o almeno riproducibili o riutilizzabili in qualsiasi altro modo (cfr. Riproducibilità della ricerca e analisi dei dati) i dati della ricerca, la pratica migliore per il loro trattamento, deve essere il più possibile aperta e FAIR, tenendo conto dei vincoli etici, commerciali e di riservatezza del trattamento di dati sensibili o dei dati chiusi.
Finalità didattiche
Essere in grado di convertire un insieme di dati "chiuso" in un insieme di dati "aperto", mettendo in atto le misure necessarie in un piano di gestione dei dati, con una gestione responsabile dei dati e dei metadati.
Essere in grado di utilizzare il piano di gestione dei dati di ricerca e di rendere i risultati della ricerca reperibili ed accessibili, anche se contengono dati sensibili.
Comprendere i pro e i contro della condivisione aperta delle diverse tipologie di dati (ad esempio, riservatezza, dati sensibili, anonimizzazione, accesso mediato).
Comprendere l'importanza di servirsi di metadati appropriati per un'archiviazione sostenibile dei dati della ricerca.
Comprendere i processi di lavoro di base nonchè gli strumenti per la condivisione dei dati della ricerca.
Componenti chiave
Conoscenze e competenze
I principi FAIR
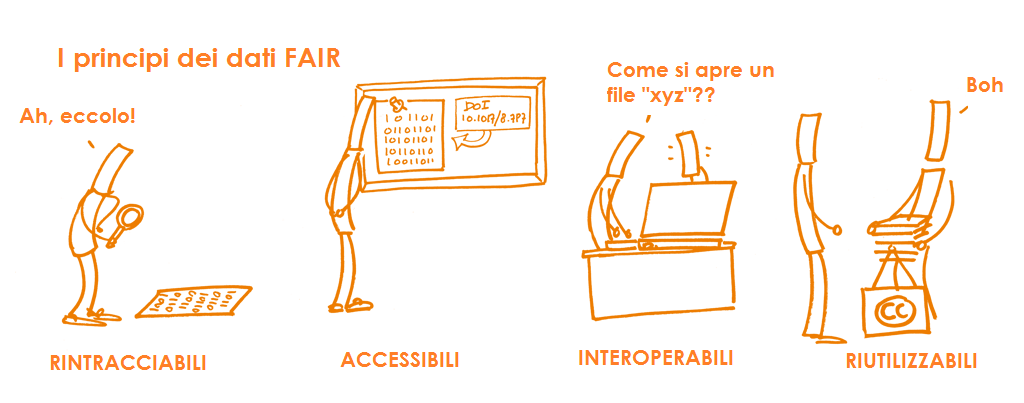
Nel 2014 vennero elaborati un gruppo di principi fondamentali, denominati principi dei dati FAIR, per ottimizzare la riutilizzabilità dei dati della ricerca. Essi rappresentano un insieme di linee guida e migliori pratiche sviluppate dalla comunità per garantire che i dati o qualsiasi oggetto digitale sia Findable / Rintracciabile, Accessible / Accessibile, Interoperable / Interoperabile e Re-usable / Riutilizzabile:
Rintracciabili: La prima cosa da fare per rendere i dati e i metadati riutilizzabili è renderli rintracciabili facilitandone la ricerca sia per gli esseri umani che per i computer. Il recupero automatico e affidabile di set di dati e servizi dipende dagli identificatori persistenti (PID) e dai metadati leggibili dalle macchine.
Accessibili: I (meta)dati devono poter essere recuperati attraverso il loro identificatore utilizzando un protocollo di comunicazione standardizzato e aperto, che includa eventualmente dei sistemi di autenticazione e autorizzazione. Inoltre, i metadati dovrebbero essere resi disponibili anche quando i dati non lo sono più.
Interoperabili: I dati devono poter essere combinati e utilizzati con altri dati o strumenti. Il formato dei dati deve pertanto essere aperto e interpretabile da vari strumenti, compresi altre basi di dati. Il concetto di interoperabilità si applica sia a livello di dati che di metadati. Ad esempio, i (metadati) dovrebbero utilizzare un linguaggio che riprende i principi FAIR.
Riutilizzabili: In sostanza, i principi FAIR mirano ad ottimizzare il riutilizzo dei dati della ricerca. A tal fine, sia i metadati sia i dati devono essere descritti nel migliore dei modi perchè possano essere replicati e/o combinati in contesti diversi. Il riutilizzo dei metadati e dei dati dovrebbe essere dichiarato con una/o più licenze chiare ed accessibili.
A differenza delle iniziative che si concentrano sul ricercatore, i principi FAIR enfatizzano in modo specifico la necessità di migliorare la capacità delle macchine di trovare e utilizzare automaticamente dei dati di ricerca o qualsiasi altro oggetto digitale, oltre a favorirne il riutilizzo da parte degli uomini/donne. I principi FAIR sono principi guida, non degli standard. I FAIR descrivono le qualità o i comportamenti necessari per rendere i dati riutilizzabili nel modo più ampio possibile (ad esempio, descrizione, citazione). Queste caratteristiche si possono ottenere mediante standard diversi.
La pubblicazione dei dati
La maggior parte dei ricercatori ha, chi più chi meno, esperienza con la pubblicazione degli articoli di ricerca e delle monografie ad accesso aperto (cfr. Capitolo 5). In tempi più recenti, e per le ragioni di cui abbiamo scritto sopra, la pubblicazione dei dati della ricerca ha assunto via via sempre più importanza ed interesse. Sono sempre di più i finanziatori che richiedono che i dati prodotti dai progetti di ricerca che hanno finanziato siano reperibili, accessibili e il più possibile aperti.
Esistono diversi modi per rendere i dati della ricerca accessibili, tra questi, ad esempio (Wikipedia):
Pubblicando i dati della ricerca come materiale supplementare in allegato ad un articolo di ricerca, tipicamente con dei file di dati pubblicati dall'editore dell'articolo.
Postando i dati della ricerca su un sito web accessibile al pubblico, con dei file che possono essere scaricati.
Depositando i dati in un archivio progettato per supportare la pubblicazione dei dati della ricerca, ad esempio, Dataverse, Dryad), figshare, Zenodo
Attraverso un considerevole numero di archivi generalisti e disciplinari oppure di archivi di dati specifici di una determinata disciplina che possono fornire un sostegno supplementare ai ricercatori nel momento in cui vogliono depositare i loro dati.
Pubblicando un documento dati sul set di dati, che può essere pubblicato come pre-print su una rivista o su una rivista di dati ad hoc per i documenti di supporto dati. I dati possono essere pubblicati su una rivista oppure separatamente in un archivio di dati. Tra le riviste di dati segnaliamo la Scientific Data (by SpringerNature) e la Data Science Journal (by CODATA). L’elenco completo delle riviste di dati è disponibile in Candela et al.
La guida CESSDA ERIC Expert tour guide on Data Management su una gestione esperta dei dati della ricerca fornisce una panoramica dei pro e contro delle diverse opzioni disponibili per la pubblicazione dei dati. A volte, l’ente finanziatore o un altro soggetto esterno richiede l'utilizzo di uno specifico archivio. Qualora non si fosse vincolati, viceversa, ad un’opzione specifica, è possibile vagliare -in ordine di preferenza- le seguenti raccomandazioni di OpenAIRE:
Utilizzare un archivio per dati della ricerca esterno o un archivio dati già reso disponibile per la propria disciplina/ambito di ricerca in modo da conservare i dati secondo gli standard riconosciuti da quella disciplina/ambito di ricerca specifico.
Laddove sia disponibile, utilizzare un archivio dati istituzionale o i servizi per la gestione dei dati della ricerca secondo le disposizioni concordate dal proprio gruppo di ricerca.
Utilizzare un archivio dati gratuito come Dataverse, Dryad, figshare o Zenodo.
Cercare altri archivi di dati in re3data. Non esiste un'unica opzione di filtro in re3data che copra i principi FAIR, ma considerando le seguenti opzioni di filtro sarà utile per trovare degli archivi FAIR-compatibili: categorie di accesso, licenze di utilizzo dei dati, archivi dati affidabili (certificati o aderenti esplicitamente agli standard di archiviazione) e se un archivio fornisce ai dati un identificativo persistente (PID). Un altro aspetto da tenere in considerazione è se l’archivio supporti o meno l’archiviazione di diverse versioni.
E’ auspicabile che si valuti dove depositare e pubblicare i dati della ricerca già con la predisposizione di un piano di gestione dei dati di ricerca. CESSDA evidenzia alcuni aspetti pratici, che si dovrebbe prendere in considerazione. Ad esempio: quali dati e relativi metadati associati, documentazione e codici verranno depositati? Per quanto tempo è necessario conservare i dati? Per quanto tempo i dati devono poter essere riutilizzabili? Come verranno resi disponibili i dati? Per quale tipologia di accessibilità si opterà? Ulteriori domande si possono trovare in Adatta il tuo Piano di gestione dei dati: parte 6. D'altra parte non si dimentichi di controllare se l’archivio prescelto soddisfa i requisiti posti dalla ricerca e dall’ente finanziatore. Alcuni depositi sono già stati certificati. Ad esempio, CoreTrustSeal che certifica l’affidabilità e il soddisfacimento dei requisiti dei Core Trustworthy Data Repositories Requirements. Vale la pena menzionare che alcuni archivi disciplinari/settoriali specifici accettano solo dati qualitativamente alti vale a dire solo quei dati che dimostrano di avere un alto potenziale di riutilizzo e che possono essere condivisi pubblicamente.
Dal momento che ci sono diversi modi per pubblicare i dati della ricerca, è bene evidenziare il fatto che un set di dati per poter "contare" come una pubblicazione, dovrebbe essere sottoposto ad un processo di pubblicazione simile a quello di un articolo (Brase et al., 2009)e dovrebbe essere:
Adeguatamente corredato di metadati;
Essere stato sottoposto ad una verifica qualitativa, ad esempio, sul contenuto dello studio, della metodologia, della pertinenza, della coerenza giuridica e della documentazione dei materiali;
Facilmente reperibile e rintracciabile in cataloghi (o banche dati);
Citabile in articoli.
Citazione dati
I servizi per la citazione dati aiutano le comunità di ricercatori a scoprire, identificare e citare i dati della ricerca (e spesso altri oggetti di ricerca) in maniera affidabile. Ciò comporta tipicamente la creazione e l'assegnazione di un identificatore digitale di un oggetto (DOI) e metadati di accompagnamento attraverso servizi come DataCite, e può essere integrato nei flussi di lavoro e gli standard di ricerca. Si tratta di un ambito in via di sviluppo e comprende molti aspetti come il fatto di far capire agli editori l'importanza di un'adeguata citazione di dati negli articoli, nonché la possibilità di collegare gli articoli di ricerca a qualsiasi dato correlato. In questo modo, i dati citabili diventano contributi legittimi al processo di comunicazione scientifica e possono contribuire a spianare la strada a nuove metriche e modelli di pubblicazione che accreditano e premiano la condivisione dei dati.
Come prima mossa iniziale verso l’adozione di buone pratiche per la citazione dati, il Gruppo di Sintesi delle Citazioni Dati di FORCE11 ha presentato una Dichiarazione congiunta sui principi per la citazione dati, destinata sia ai ricercatori sia ai fornitori di servizi dati. Conformemente a questi principi, gli archivi dati, di solito, forniscono ai ricercatori una citazione di riferimento che possono utilizzare quando si riferiscono a un determinato set di dati.
Confezionamento dei dati
I pacchetti di dati servono per descrivere e condividere i file di dati che li accompagnano; di solito sono composti da un file di metadati che descrive le caratteristiche e il contesto di un determinato set di dati. Il file può includere aspetti come informazioni sulla creazione dei dati, la provenienza, le dimensioni, il tipo di formato, le definizioni dei campi, così come tutti i file contestuali rilevanti, come gli script per la creazione dei dati o la documentazione testuale. La Data Packaging Guide dice:
I dati sono per sempre: i set di dati sopravvivono allo scopo per cui sono stati originati. Le limitazioni dei dati possono essere dati per scontati nel loro contesto originale, come nel caso di un catalogo bibliotecario, ma possono non esserlo una volta che gli stessi dati sono stati separati dall'applicazione per la quale erano stati creati.
I dati non possono stare da soli: informazioni sul contesto, la provenienza del dato - come e perché è stato creato, quali oggetti e concetti reali rappresenta, i vincoli sui valori - sono necessari per aiutare gli utenti ad interpretarli in maniera responsabile.
Il fatto di strutturare e standardizzare dei metadati per i set di dati che possano anche essere leggibili dalle macchine è un modo per incoraggiare la promozione, la condivisione e il riutilizzo dei dati.
La condivisione di dati sensibili e di dati chiusi
Un'adeguata pianificazione della gestione dei dati, può essere essenziale perchè molti dati sensibili e dati chiusi possano essere condivisi, riutilizzati e FAIR. I metadati possono essere condivisi quasi sempre. Le linee guida e le migliori pratiche per la condivisione dei dati sensibili sono necessariamente specifiche regione per regione facendo riferimento a normative diverse (si veda ad esempio il manuale UKDS'Companion Material for Managing and Sharing Research Data Handbook). L'International Association for Social Science Information Services and Technology si occupa di aggiornare un elenco di linee guida internazionali per la gestione dei dati e rappresenta un buon punto di partenza. Esistono diversi approcci e iniziative per aiutare i ricercatori a raggiungere questo obiettivo. DMPonline del DCC raccoglie una serie di modelli per gli enti finanziatori. La guida CESSDA sulla gestione dei dati fornisce informazioni ed esempi pratici su come condividere i dati personali e su questioni relative al diritto d’autore e database in tutti i paesi europei. La guida fornisce anche una panoramica sull'impatto del GDPR, finalizzato ad armonizzare le legislazioni europee sui dati personali (e introdotto nel maggio 2018) fornisce altresì una panoramica aggiornata sulle divergenze in materia di protezione dei dati nei diversi stati membri EU diversity on data protection.
Gli intermediari di dati
Gli intermediari di dati sono esperti indipendenti e competenti che operano come degli amministratori di dati, ovvero, nel caso specifico, amministratori di dati sensibili. I ricercatori possono conferire all’intermediario i loro dati sensibili e la normativa sull'accesso a quei dati. Questo succede in particolare quando si tratta di dati relativi a pazienti che compaiono in studi clinici. Gli intermediari garantiscono un livello di indipendenza nella valutazione delle richieste di dati scientificamente validi e non violano la riservatezza di chi partecipa alla ricerca. Esempi di intermediari di dati si trovano nel progetto The YODA Project, ClinicalStudyDataRequest.com, National Sleep Research Resource and Supporting Open Access for Researchers (SOAR).
Portali di analisi
I portali di analisi sono piattaforme che consentono l'analisi approvata di dati ma non consentono l'accesso completo (visualizzazioni o download) o la rintracciabilità della provenienza e identità dell’utente che accede alla piattaforma. Alcuni intermediari di dati utilizzano anche i portali di analisi. I portali di analisi controllano quali set di dati aggiuntivi possono essere associati con i dati sensibili e quali analisi possono essere eseguite per garantire che non vengano divulgate informazioni personali durante successive analisi. Esempi di portali di analisi virtuali sono Project Data Sphere, Vivli, RAIRD, Corpuscle, and INESS.
Le scienze sociali e altri ricercatori che trattano dati sensibili utilizzano un portale di analisi, in un unico sito a cui si può accedere solo in regime controllato. I ricercatori autorizzati possono accedere ai dati sul posto, in una camera blindata, per scopi scientifici. Tuttavia, i metadati che descrivono i dati dovrebbero essere liberamente disponibili e conformi ai principi di FAIR.
Anonimizzazione e dati sintetici
Molti set di dati contenenti informazioni private a livello-partecipanti possono essere condivisi una volta che il set di dati è stato anonimizzato (metodo del porto sicuro) o un esperto ha stabilito che il set di dati non è individualmente identificabile (metodo della determinazione esperta). Consultate il vostro Comitato Etico della Ricerca / Comitato di controllo istituzionale per capire come procedere con i vostri dati oppure consultate la guida sulla gestione dei dati CESSDA che fornisce informazioni ed esempi pratici su come condividere i dati personali. Tuttavia, alcuni set di dati non possono essere identificati e condivisi in modo sicuro. I ricercatori possono ulteriormente migliorare il livello di apertura della ricerca su tali dati creando e condividendo dati sintetici. I dati sintetici sono simili nella struttura, nel contenuto e nella distribuzione ai dati reali e mirano a raggiungere "validità analitica": l'analisi statistica otterrà gli stessi risultati per i dati sintetici e per i dati reali. L'United States Census Bureau, ad esempio, utilizza dati sintetici e portali di analisi in combinazione per consentire il riutilizzo di dati altamente sensibili.
DataTags
DataTags è un sistema progettato per consentire di valutare con l’assistenza di un computer le restrizioni legali, contrattuali nonché le politiche che regolamentano le decisioni sulla condivisione dei dati. Il sistema DataTags pone all'utente una serie di domande per sintetizzare le proprietà peculiari di un determinato set di dati; il sistema applica quindi delle regole di inferenza per individuare quali leggi, contratti e migliori pratiche sia più opportuno adottare. La risposta del sistema è un insieme di raccomandazioni (DataTags) ovvero delle semplici etichette iconiche che corrispondono ad una specifica politica dei dati leggibile dall'uomo e dalle macchine, e un contratto di licenza su misura per uno specifico set di dati. Il sistema DataTags è stato progettato per poter essere integrato con i software di archiviazione dati ma può funzionare anche autonomamente. L'Università di Harvard si sta occupando di sviluppare ulteriormente le funzionalità dei DataTags mentre in Europa il DANS sta lavorando sui DataTags per adeguarlo alla legislazione europea / Regolamento Generale sulla Protezione dei Dati (GDPR) (cfr. DANS GDPR DataTags).
Come si è già accennato, l'obiettivo finale della condivisione dei dati della ricerca è quello di renderli il più possibile riutilizzabili. A tal fine, prima di condividere i dati, è necessario gestirli secondo le migliori pratiche. Ciò include, tra l'altro, la documentazione e la scelta dei formati di file aperti e delle licenze. Per ulteriori informazioni su questi aspetti, cfr. capitolo 4: La reproducibilità della ricerca e l'analisi dei dati e il Capitolo 6: Licenze aperte e formati di file.
Materiali aperti
Oltre alla condivisione dei dati, l'apertura della ricerca si basa sulla condivisione dei materiali. I materiali che i ricercatori utilizzano sono specifici per disciplina e talvolta unici per un laboratorio. Di seguito sono riportati alcuni esempi di materiali che si possono condividere, anche se è sempre consigliabile confrontarsi con i propri colleghi o ricercatori nel proprio ambito disciplinare per identificare quali archivi vengano utilizzati. Una volta che materiali, dati e pubblicazioni dello stesso progetto di ricerca sono stati condivisi in diversi archivi, è opportuno incrociare i diversi riferimenti con un link e un identificatore unico in modo che possano essere facilmente localizzati.
Reagenti
Un reagente è una sostanza, un composto o una miscela che può essere aggiunta ad un sistema per creare una reazione chimica o di qualsiasi altro tipo. I reagenti possono essere aggiunti in depositi come Addgene, The Bloomington Drosophila Stock Center, e ATCC per renderli facilmente accessibili ad altri ricercatori. Applicate una licenza ai vostri materiali di ricerca in modo che possano essere riutilizzati da altri ricercatori.
Protocolli
Un protocollo descrive la memoria formale o ufficiale di osservazioni scientifiche sperimentali attraverso un modello strutturato. Dei protocolli virtuali si possono depositare per la citazione, l'adattamento e il riutilizzo utilizzando Protocols.io.
Notebook, container, software e hardware
L'analisi riproducibile è supportata dall'uso di una programmazione alfabetizzata, di tecnologie dei container e virtualizzazione. Oltre a condividere il codice e i dati, è possibile condividere anche i notebook Jupyter, le immagini Docker o altri materiali di analisi o dipendenze software. I notebook possono essere condivisi tramite i servizi aperti come mybinder che consentono la visualizzazione pubblica e l'esecuzione dell'intero notebook su risorse condivise. Contenitori e notebook possono essere condivisi con Rocker or Code Ocean. Il software e l'hardware utilizzati per le vostre ricerche devono essere condivisi seguendo le migliori pratiche per la documentazione, come indicato nel Capitolo 3. I protocolli di sola lettura devono essere depositati nel registro delle discipline come ClinicalTrials.gov e SocialScienceRegistry o in un registro generale come Open Science Framework. Molte riviste, come Trials, JMIR Research Protocols, o Bio-Protocol pubblicano i protocolli. Le migliori pratiche per la pubblicazione del protocollo ad accesso aperto sono le stesse della pubblicazione della relazione aperta (cfr. Capitolo 5).
Domande, intoppi ed equivoci comuni
Domanda: Può bastare rendere i dati della ricerca disponibili apertamente?
Risposta: No, l’apertura è una condizione necessaria ma non sufficiente per ottenere il massimo ri-utilizzo. I dati devono essere FAIR oltre ad essere aperti.
Domanda: In che modo i diversi attori/platee percepiscono/sottintendono quando parlano di principi FAIR?
Risposta: Questo è un argomento interessantissimo su cui discutere!
Ostacolo: I ricercatori possono essere riluttanti a condividere i loro dati perché temono che altri li riutilizzino prima di averne estrapolato il massimo potenziale di utilizzo, o che altri non possano comprendere del tutto questi dati e quindi abusarne.
(suggerito) Risposta: Potete pubblicare i vostri dati per renderli reperibili con metadati, ma fissate un periodo di embargo sui dati per essere sicuri di poter pubblicare prima i vostri articoli.
Domanda: "Quanto lavoro extra implica fare in modo che i dati di ricerca siano FAIR?"
Risposta: "Non per forza tanto! Rendere i dati FAIR non è solo responsabilità dei singoli ricercatori ma dell'intero gruppo di ricerca. Il modo migliore per garantire che i vostri dati siano FAIR è quello di creare un piano di gestione dei dati e pianificare tutto in anticipo. Durante la raccolta e l'elaborazione dei dati seguire gli standard disciplinari e le misure raccomandate dall’archivio.
Domanda: "Voglio condividere i miei dati. Quale licenza è meglio che io scelga?
Risposta: "Questa è una buona domanda. Prima di tutto dovete domandarvi di chi sono i dati: dell’ente finanziatore della ricerca o dell'istituzione presso la quale lavorate? Pensate poi alla paternità. Applicare una licenza adeguata ai dati è fondamentale per renderli riutilizzabili. Per maggiori informazioni sulle licenze, (cfr. Capitolo 6. Licenze aperte e formati di file).
Domanda: "Non posso rendere i miei dati subito disponibili - sono troppi per poterli condividere facilmente / hanno restrizioni di riservatezza. Cosa devo fare?
Risposta: Dovresti consultarti con personale esperto in archivi disciplinari o settoriali e chiedere come puoi fornire indicazioni sufficienti per rendere i tuoi dati reperibili e accessibili.
Risultati di apprendimento
Comprensione delle caratteristiche specifiche dei dati della ricerca aperti, in particolare secondo i principi FAIR.
Padroneggiare alcune argomentazioni pro e contro circa i dati aperti.
Essere in grado di distinguere e trattare i dati sensibili e i dati opFAIR; queste due categorie non sono necessariamente incompatibili.
Essere in grado di trasformare un set di dati in un set di dati condivisibili apertamente (in formato non chiuso), in grado di soddisfare gli standard dei principi FAIR, progettato per massimizzare accessibilità, trasparenza e riutilizzo con un numero minimo di metadati.
Conoscere la differenza tra i dati grezzi e quelli elaborati (o puliti) e l'importanza delle etichette di versione.
Conoscere i formati di file comunemente usati e gli standard comunitari per ottenere il massimo livello di riutilizzabilità.
Essere in grado di scrivere un piano di gestione dei dati.
Letture integrative
Averkamp et al. (2018). Data packaging guide. github.com/saverkamp/beyond-open-data/blob/master/DataGuide.md.
Barend et al. (2017). Cloudy, increasingly FAIR; revisiting the FAIR Data guiding principles for the European Open Science Cloud. doi.org/10.3233/ISU-170824
Brase et al. (2009). Approach for a joint global registration agency for research data. doi.org/10.3233/ISU-2009-0595
Candela et al. (2015). Data journals: A survey. doi.org/10.1002/asi.23358
CESSDA Training Working Group (2017-2018a). CESSDA Data Management Expert Guide. Bergen, Norway: CESSDA ERIC. cessda.eu/DMGuide
CESSDA Training Working Group (2017-2018b). CESSDA Data Management Expert Guide: Citing your data. Bergen, Norway: CESSDA ERIC.cessda.eu/DMGuide/citingdata
FAIRsharing.org (2016). FAIR. The FAIR Principles. doi.org/10.25504/FAIRsharing.WWI10U
Force 11 (n.y.). Guiding principles for Findable, Accessible, Interoperable, and Re-usable data publishing Version B1.0. force11.org/fairprinciples
Gorgolewski et al. (2013). Making data sharing count: a publication-based solution. doi.org/10.3389/fnins.2013.00009
Kratz and Strasser (2015). Making Data Count. doi.org/10.1038/sdata.2015.39
Piwowar and Vision (2013). Data reuse and the open data citation advantage. doi.org/10.7717/peerj.175
Wilkinson et al. (2016). The FAIR Guiding Principles for scientific data management and stewardship. doi.org/10.1038/sdata.2016.18
Wilkinson et al. (2918). A design framework and exemplar metrics for FAIRness. doi.org/10.1038/sdata.2018.118
Iniziative e progetti
DANS GDPR DataTags. zingtree.com
FAIR Metrics. fairmetrics.org
GO FAIR Initiative. go-fair.org
The FAIR Data Principles explained. go-fair.org
5★ OPEN DATA. 5stardata.info